#这是一个把浮点数变成float32储存字节的算法 deftrans_to_byte(A): if A >= 0 : symbol = "1" else: symbol = "0" print("符号位:",symbol) A = abs(A) count = 0 while A > 1: A = A /2 count+= 1 exp = "" for i inrange(8-len(bin(5).split("0b")[1])): exp = exp+"0" exp += bin(count).split("0b")[1] print("指数位:",exp) remain = "" for i inrange(1,24): if A-2**(-i)>=0: remain = remain + "1" A = A - 2**(-i) else: remain = remain + "0" A = A print("尾数:",remain) return(symbol+exp+remain) trans_to_byte(-0.55)
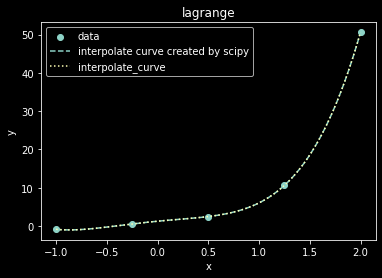
# scipy的拉格朗日插值 from scipy.interpolate import lagrange x=np.linspace(-1,2,5) y = np.exp(2*x)-x**2 poly = lagrange(x, y) x1 = np.linspace(-1,2,1000)
#手算的插值 deflagrange_dyf(x,y,x_target): result = 0 component = list() for i inrange(len(x)): tem = 1 #计算第n个插值多项式 for j inrange(0,i): tem *= (x_target - x[j])/(x[i] - x[j]) for j inrange(i+1,len(x)): tem *= (x_target - x[j])/(x[i] - x[j]) tem *= y[i] result += tem return result
%matplotlib inline fig, ax = plt.subplots(1) plt.scatter(x,y,label ="data") plt.plot(x1,[poly(i) for i in x1],label = r"interpolate curve created by scipy",linestyle = "--") plt.plot(x1,[lagrange_dyf(x,y,i) for i in x1],label = r"interpolate_curve",linestyle = ":") ax.legend(); # Add a legend. ax.set_xlabel('x') # Add an x-label to the axes. ax.set_ylabel('y') # Add a y-label to the axes. ax.set_title("lagrange") # Add a title to the axes. plt.show()
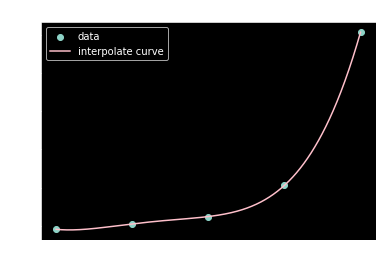
defNewton_interpolate_dyf(x,y,x_target): func = dict(zip(x,y)) defget_ceff(X): # 得到 f[x0,x1,x2..xn]的函数,X是一个[x0,x1,x2,..xn]的列表 iflen(X)==1 : return func[X[0]] else: return (get_ceff(X[1:len(X)]) - get_ceff(X[0:len(X)-1]))/(X[-1]-X[0]) result = 0 for i inrange(0,len(x)): # print('在算第'+str(i+1)+'个项,系数为',x[0:i+1]) poly = 1 for j inrange(0,i): poly *= x_target-x[j] # print("多",poly,x[i],x_target) result += get_ceff(x[0:i+1])*poly #print(result) return result
x=np.linspace(-1,2,5) y = (np.exp(2*x)-x**2).tolist() x = x.tolist() x1 = np.linspace(-1,2,1000)
%matplotlib inline fig, ax = plt.subplots(1) plt.scatter(x,y,label ="data") plt.plot(x1,[Newton_interpolate_dyf(x,y,i) for i in x1],label = r"interpolate curve",color = "pink") ax.legend(); # Add a legend. ax.set_xlabel('x') # Add an x-label to the axes. ax.set_ylabel('y') # Add a y-label to the axes. ax.set_title("Newton") # Add a title to the axes. plt.show()
5 数值积分
5.1 简单积分方法:梯形积分
积分公式:
\[
T = \sum_{i}{(f(x_i)+f(x_{i+1}))\frac{\Delta x_i}{2}}
\]
#f(x) = sin(x) a = 0 ,b = pi defintergrate_Trapezoid(func,a,b,N): x = np.linspace(a,b,N) w = (b-a)/N y = [func(i) for i in x] T = 0 for i inrange(len(x)-1): T += (y[i] + y[i+1])*w/2 return T print(intergrate_Trapezoid(np.sin,0,np.pi,100000))
import scipy.integrate as integrate print(integrate.quad(np.sin,0,np.pi))
\[
I = \frac{x_2-x_0}{6}[f(x_0)+4f(x_1)+f(x_2)]
\]
误差分析方法同上,就不写了
1 2 3 4 5 6 7 8 9 10 11 12
defintergrate_simpson(func,a,b,N): x = np.linspace(a,b,N) w = (b-a)/N T = 0 for i inrange(len(x)-1): T += (func(x[i])+4*func((x[i]+x[i+1])/2)+func(x[i+1]))*w/6 return T
print(intergrate_simpson(np.sin,0,np.pi,1000000))
import scipy.integrate as integrate print(integrate.quad(np.sin,0,np.pi))
from scipy.special import roots_legendre #用于得到对应的高斯点
defintegrate_gauss(func,a,b,N): x = np.linspace(a,b,N) w = (b-a)/N T = 0 for i inrange(len(x)-1): T += w/2*(func(w/2/np.sqrt(3)+x[i]+w/2)+func(-w/2/np.sqrt(3)+x[i]+w/2)) return T print(integrate_gauss(np.sin,0,np.pi,100000))
defintegrate_gauss_n(func,a,b,N,n):#n是高斯点的个数 x = np.linspace(a,b,N) w = (b-a)/N T = 0 x_gauss,a = roots_legendre(n) # scipy可以方便得到高斯点w以及对应的权重a for i inrange(len(x)-1): for j inrange(len(x_gauss)): T += a[j]*w/2*func(w/2*x_gauss[j]+x[i]+w/2) return T print(integrate_gauss_n(np.sin,0,np.pi,100000,5))
横坐标对应于\(w_l= \frac{2\pi l }{N\Delta
t}\),\(\Delta t\)为取样间隔
将 $f(t) =e{-200t2} $ 做DFT变换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
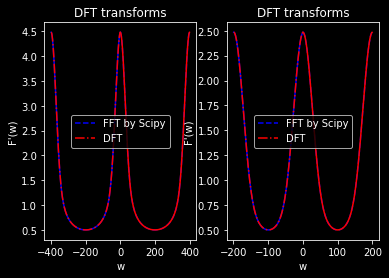
t_end = 1 N = 400#不能少于两个点 t = np.linspace(0,2*np.pi*t_end,N)#是等距的点 delta_t = t[1] - t[0] y = np.exp(-t**2*200)
defDFT_trans(f):#f是传入其中的采样点的np.array F = list() N = len(f) for k inrange(N): tem = 0#容器 for l inrange(N): tem += f[l]*np.exp(-1.j*k*2*np.pi*l/N) F.append(tem) return np.array(F)
w0 = np.linspace(-2*np.pi/delta_t,0,N) w1 = np.linspace(0,2*np.pi/delta_t,N) %matplotlib inline fig, ax = plt.subplots(1,2) #plt.scatter(x,y,label ="data") ax[0].plot(w1,abs(fft.fft(y)),label = r"FFT by Scipy",color="blue",linestyle = "--") ax[0].plot(w0,abs(fft.fft(y)),color="blue") ax[0].plot(w0,abs(DFT_trans(y)),label = r"DFT",color="red",linestyle = "-.") ax[0].plot(w1,abs(DFT_trans(y)),color="red") ax[0].legend(); # Add a legend. ax[0].set_xlabel('w') # Add an x-label to the axes. ax[0].set_ylabel('F\'(w)') # Add a y-label to the axes. ax[0].set_title("DFT transforms") # Add a title to the axes.
## 更改点数后再画 N = 200#不能少于两个点 t = np.linspace(0,2*np.pi*t_end,N)#是等距的点 delta_t = t[1] - t[0] y = np.exp(-t**2*200) w0 = np.linspace(-2*np.pi/delta_t,0,N) w1 = np.linspace(0,2*np.pi/delta_t,N)
ax[1].plot(w1,abs(fft.fft(y)),label = r"FFT by Scipy",color="blue",linestyle = "--") ax[1].plot(w0,abs(fft.fft(y)),color="blue") ax[1].plot(w0,abs(DFT_trans(y)),label = r"DFT",color="red",linestyle = "-.") ax[1].plot(w1,abs(DFT_trans(y)),color="red") ax[1].legend(); # Add a legend. ax[1].set_xlabel('w') # Add an x-label to the axes. ax[1].set_ylabel('F\'(w)') # Add a y-label to the axes. ax[1].set_title("DFT transforms") # Add a title to the axes. plt.show()
A =np.array([[1,3,1],[3,10,4],[1,4,4]]) U = Cholesky_factorization(A) L = U.transpose() b = np.array([0,2,-1/3]) #先求解y y = [b[0]/L[0][0]] #先把y1处理了 for i inrange(1,len(b)): tem = b[i] for j inrange(0,i): tem = tem - L[i][j]*y[j] tem = tem/L[i][i] y.append(tem) print("y:",y) #求解x x = np.zeros(len(y)) x[-1] = y[-1]/U[-1][-1]#先把y1处理了 for i inrange(len(y)-1,-1,-1): tem = y[i] for j inrange(len(y)-1,i,-1): tem = tem - U[i][j]*x[j] tem = tem/U[i][i] x[i] = tem print("x:",x)
\[\begin{aligned}
&L_1^{-1}..L_{n-1}^{-1}L_n^{-1}L_nL_{n-1}...L_1 A
\\\\&= S (L_nL_{n-1}...L_1 A) = SU = A
\\\\&S= L_1^{-1}..L_{n-1}^{-1}L_n^{-1}
\end{aligned}\]
#假设是A是full pivoting的,也就是恰当排序使得在分解过程中不存在对角元为0的情况 defgauss_elimination_LU(A): #a是系数矩阵,b是方程的非齐次值,a得满足一定条件,先将a分解成LU矩阵 N = A.shape[0] L = np.identity(N) for i inrange(0,N): if A[i][i] != 0: for j inrange(i+1,N):#消去 if A[i][j] != 0: tem = A[i][j]/A[i][i] A[j] = A[j] - tem*A[i] L[j][i] = tem else: pass else: print("A不是恰当排序的") return0 return L,A
defQR_factorization(A):#为了简单,这里讨论实数矩阵 A = np.array(A,dtype=float) N = A.shape[0] Householder_Matrix = list() for i inrange(N-1): #来源于参考文献 #print(A[i:,i]) alpha = np.linalg.norm(A[i:,i]) signi = np.sign(A[i][i]) rho = -signi * alpha nu1 = A[i][i] - rho u2 = A[i+1:,i]/nu1 tau = (1 + np.dot(u2,u2))/2 #记录使用的Householder变换的矩阵 tem_matrix = np.identity(N,dtype = float) tem_matrix[i:,i:] = np.identity(N-i) - np.outer(np.insert(u2,0,1),np.insert(u2,0,1))/tau Householder_Matrix.append(tem_matrix) #print(Householder_Matrix[-1]) #print(np.matmul(Householder_Matrix[-1],A)) #手动求解变换后的对角矩阵,减少矩阵运算的次数 A[i][i] = rho for j inrange(i+1,N): A[j][i] = 0 w12T = (A[i,i+1:] + np.matmul(A[i+1:,i+1:],u2))/tau A[i,i+1:] = A[i,i+1:] - w12T A[i+1:,i+1:] = A[i+1:,i+1:] - np.outer(u2,w12T) Q = np.identity(N) for j in Householder_Matrix: Q = np.matmul(Q,j) return Q,A
1 2 3 4 5 6 7 8 9 10 11 12 13 14
A = np.array([[3,3,1],[3,5,2],[1,2,3]]) defget_eigen_values(A):#A是一个有特征值的实矩阵,没写判断条件,所以用的实对称矩阵检验 tol = 1 N = A.shape[0] for i inrange(0,10000): tol = 0 Q,R = QR_factorization(A) A = np.matmul(R,Q) for i inrange(0,N): for j inrange(N-1,i,-1): tol += np.abs(A[j][i]) return np.array([A[i][i] for i inrange(N)]) print(get_eigen_values(A)) np.linalg.eigvals(A)